2021 Blog, SPECTRA Blog, Blog, Featured
Simplify and Speed-Up Oracle Fusion Reporting with RL SPECTRA
Oracle Fusion is an invaluable support to many businesses for managing their transaction data. However, business users would be familiar with limitations when it comes to generating even moderately complex analyses and reports involving a large volume of data. In a Big Data-driven world, this can become a major competitive disadvantage. Relevance Lab has designed SPECTRA, a Hadoop-based platform, that makes Oracle Fusion reports simple, quick, and economical even when working with billions of transaction records.
Challenges with Oracle Fusion Reporting
Oracle Fusion users often struggle to extract reports from large transactional databases. Key issues include:
- Inability to handle large volumes of data to generate accurate reports within reasonable timeframes.
- Extracting integrated data from different modules of the ERP is not easy. It requires manual effort for synthesizing fragmented reports, which makes the process time-consuming, costly, and error-prone. Similar problems arise when trying to combine data from the ERP with that from other sources.
- The reports are static, not permitting a drill down on the underlying drivers of reported information.
- There are limited self-service operations, and business users have to rely heavily on the IT department for building new reports. It is not uncommon for weeks and months to pass between the first report request and the availability of the report.
Moreover, Oracle has stopped supporting its reporting tool Discoverer from 2017, creating additional challenges for users that continue to rely on it.
How RL SPECTRA can Help
Relevance Lab recognizes the value to its clients of generating near real-time dynamic insights from large, ever-growing data volumes at reasonable costs. With that in mind, we have developed an Enterprise Data Lake (EDL) platform, SPECTRA, that automates the process of ingesting and processing huge volumes of data from the Oracle Cloud.
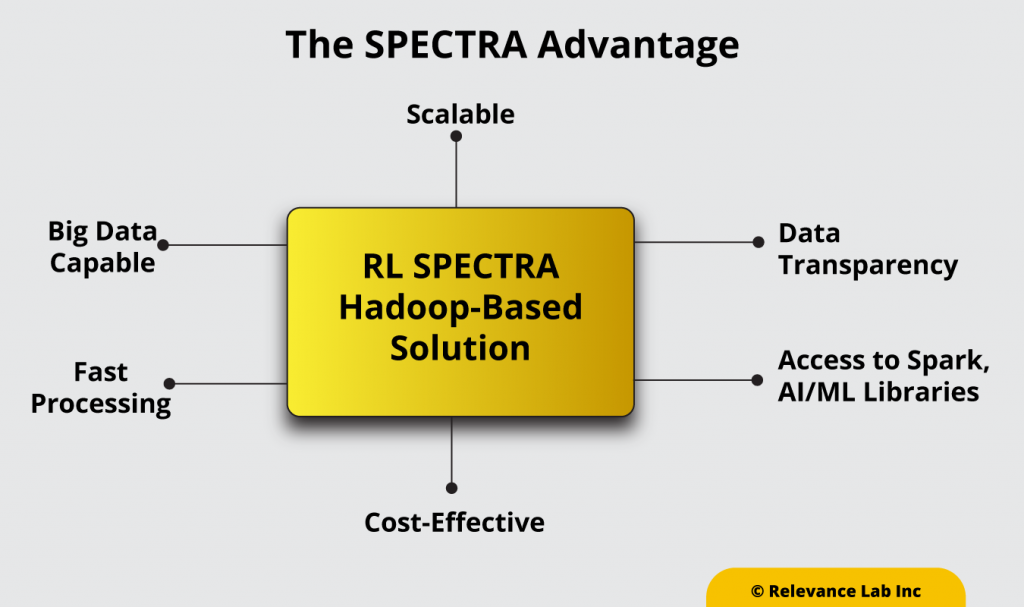
This Hadoop-based solution has advantages over traditional data warehouses and ETL solutions due to its:
- superior performance through parallel processing capability and robustness when dealing with large volumes of data,
- rich set of components like Spark, AI/ML libraries to derive insights from big data,
- a high degree of scalability,
- cost-effectiveness, and
- ability to handle semi-structured and unstructured data.
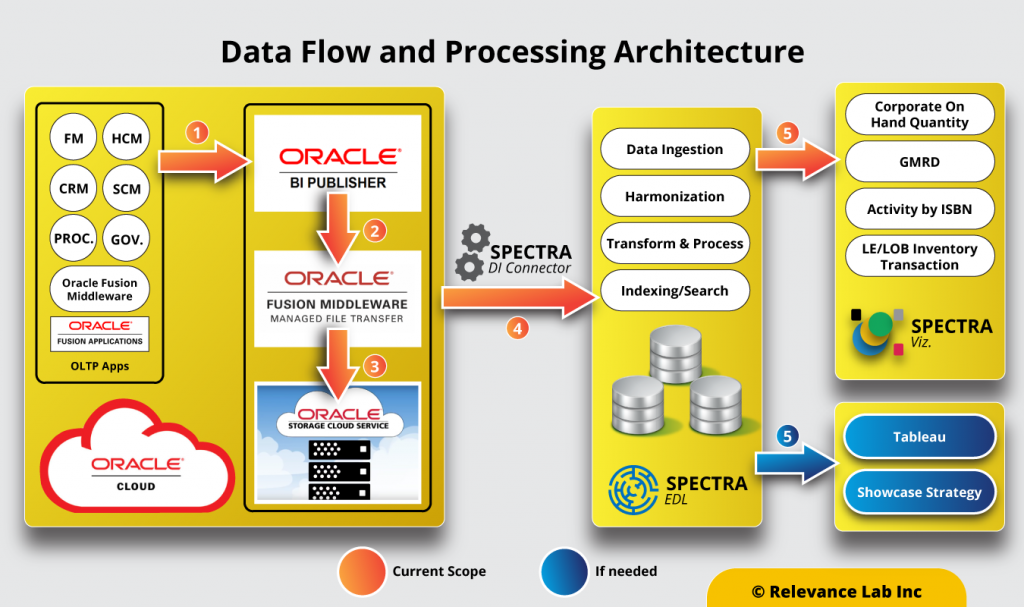
After the initial data ingestion into the EDL, incremental data ingestion uses delta refresh logic to minimize the time and computing resources spent on ingestion.
SPECTRA provides users access to raw data (based on authorization) empowering them to understand and analyze data as per their requirement. It enables users to filter, sort, search & download up to 6 million records at one go. The platform is also capable of visualizing data in charts, apart from being compatible with standard dashboard tools.
This offering combines our deep Oracle and Hadoop expertise with extensive experience across industries.
With this solution, we have helped companies generate critical business reports from massive volumes of underlying data delivering substantial improvement in extraction and processing time, quality, and cost-effectiveness.
Use Case: Productivity Enhancement through Optimised Reporting for a Publishing Major
A global publishing major that had recently deployed Oracle Fusion Cloud applications for inventory, supply chain, and financial management discovered that these were inadequate to meet its complex reporting and analytical requirements.
- The application was unable to accurately process the company’s billion-plus transaction records on the Oracle Fusion Cloud to generate a report on the inventory position.
- It was also challenging to use an external tool to do this as it would take several days to extract data from the Oracle cloud to an external source while facing multiple failures during the process.
- This would make the cost and quality reconciliation of copies of books lying in different warehouses and distribution centres across the world very difficult and time-consuming, as business users did not have on-time and accurate visibility of the on-hand quantity.
- In turn, this had adverse business consequences such as inaccurate planning, higher inventory costs, and inefficient fulfilment.
The company reached out to Relevance Lab for a solution. Our SPECTRA platform automated and optimized the process of data ingestion, harmonization, transformation, and processing, keeping in mind the specific circumstances of the client. The deployment yielded multiple benefits:
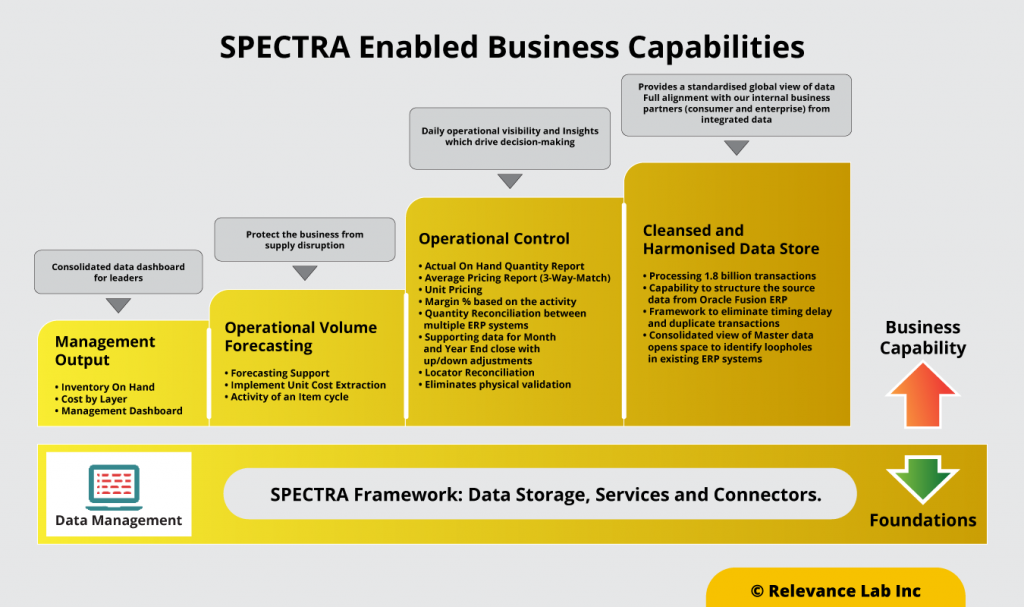
- On-Hand quantity and costing reports are now generated in less than an hour
- Users can access raw data as well as multiple reports with near real-time data, giving them full flexibility and making the business more responsive to market dynamics
- Overall, user efforts stand reduced by 150 hours per person per quarter by using SPECTRA for their inventory report, leading to higher productivity
- With all the raw data in SPECTRA, several reconciliation procedures are in place to identify missing data between the Oracle cloud and its legacy system
The Hadoop-based architecture can be scaled flexibly in response to the continuously growing size of the transaction database and is also compatible with the client’s future technology roadmap.
Conclusion
RL’s big-data platform, SPECTRA, offers an effective and efficient future-ready solution to the reporting challenges in Oracle Fusion when dealing with large data sets. SPECTRA enables clients to access near real-time insights from their big data stored on the Oracle Cloud while delivering substantial cost and time savings.
To know more about our solutions or to book a call with us, please write to marketing@relevancelab.com.

