2022 Blog, Analytics, SPECTRA Blog, Blog, Featured
The Consumer Packaged Goods (CPG) Industry is one of the largest industries on the planet. From food and beverage to clothes to stationary, it is impossible to think of a moment in our lives without being touched or influenced by this sector. If there is one paradigm around which the industry revolves, regardless of the sub-sector or the geography, it is the fear of stock outs. Studies indicate that when a customer finds a product unavailable, 31% are likely to switch over to a competitor when it happens for the first time. It becomes 50% when this occurs for a second time and rises to 70% when this happens for a third time.
Historically, the panacea for this problem has been to overstock. While this reduced the risk of stock outs to a great extent, it induced a high cost for holding the inventory and increased risk of obsolescence. It also created a shortage of working capital since a part of it is always locked away in holding excess inventory. This additional cost is often passed on to the end customer. Over time, an integrated planning solution which could predict demand, supply and inventory positions became a key differentiator in the CPG industry since it helped rein in costs and become competitive in an industry which is extremely price sensitive.
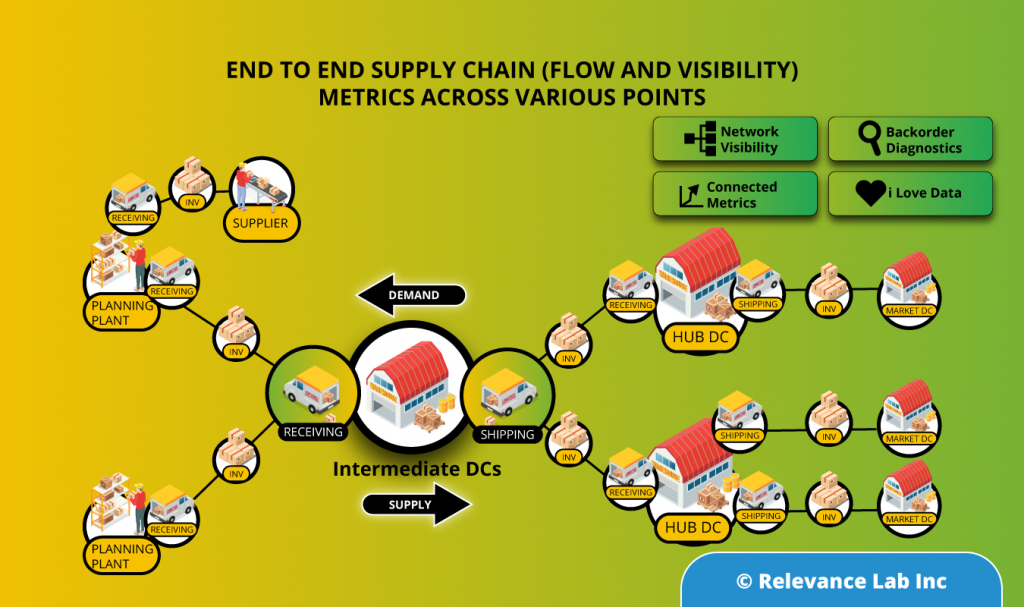
Although theoretically, a planning solution should have been able to solve the inventory puzzle, practically, a lot of challenges kept limiting its efficacy. Conventional planning solutions have been built based on local planning practices. Such planning solutions have had challenges negotiating the complex demand patterns of the customers which are influenced by general consumer behaviour and also seasonal trends in the global market. As a result the excess inventory problem stays, which gets exacerbated at times due to bullwhip effect.
This is where the importance of a global integrated Production Sales Inventory (PSI) solutions comes in. But usually, this is easier said than done. Large organizations face multiple practical challenges when they attempt to implement this. Following are the typical challenges that large organizations face
- Infrastructural Limitations
Using conventional systems of Business Intelligence of Planning systems would require very heavy investment in infrastructure and systems. Also the results may not be proportionate to the investments made. - Data Silos
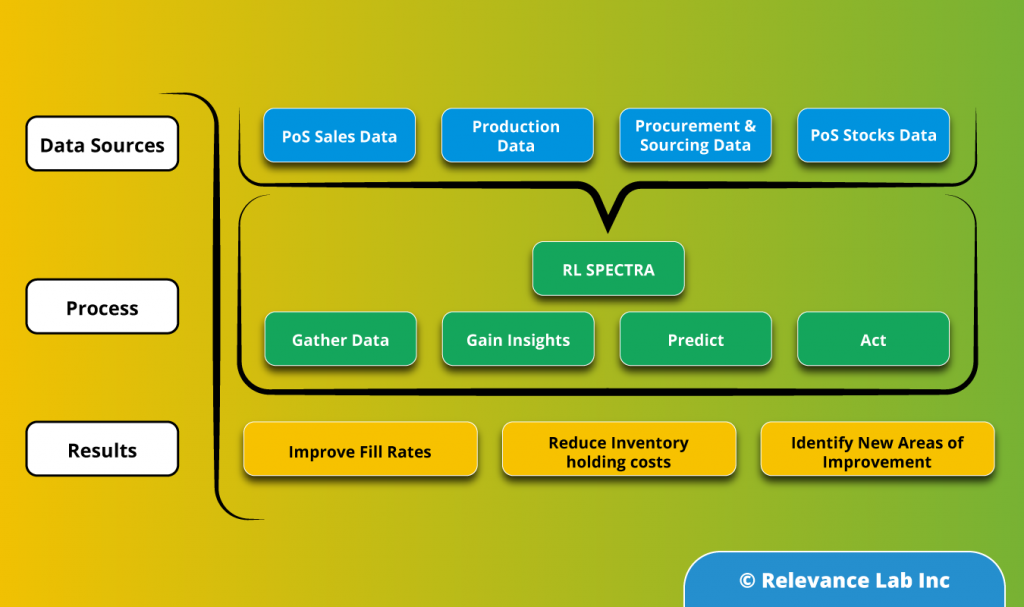
PSI requires data from different departments including sales, production, and procurement/sourcing. Even if the organization has a common ERP, the processes and practices in each department might make it difficult to combine data and get insights.
Another significant hurdle is the fact that larger organizations usually tend to have multiple ERPs for handling local transactions aligned to geographical markets. Each ERP or data source which does not talk to other systems becomes siloed. The complexities increase when the data formats and tables are incompatible, especially, when the ERPs are from different vendors. - Manual Effort
Harmonizing the data from multiple systems and making them coherent involves a huge manual effort in designing, building, testing and deployment if we follow conventional mode. The prohibitive costs involved, not to mention the human effort involved is a huge challenge for most organizations.
Relevance Lab has helped multiple customers tide over the above challenges and get a faster return on their investments.
Here are the steps we follow to achieve a responsive global supply chain
- Gather Data: Collate data from all relevant systems
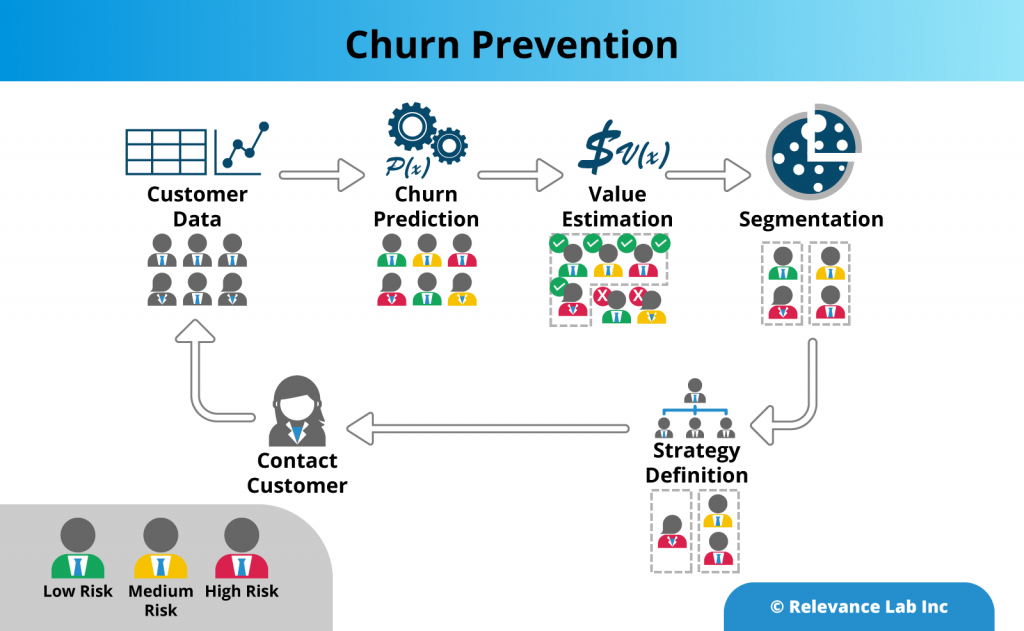
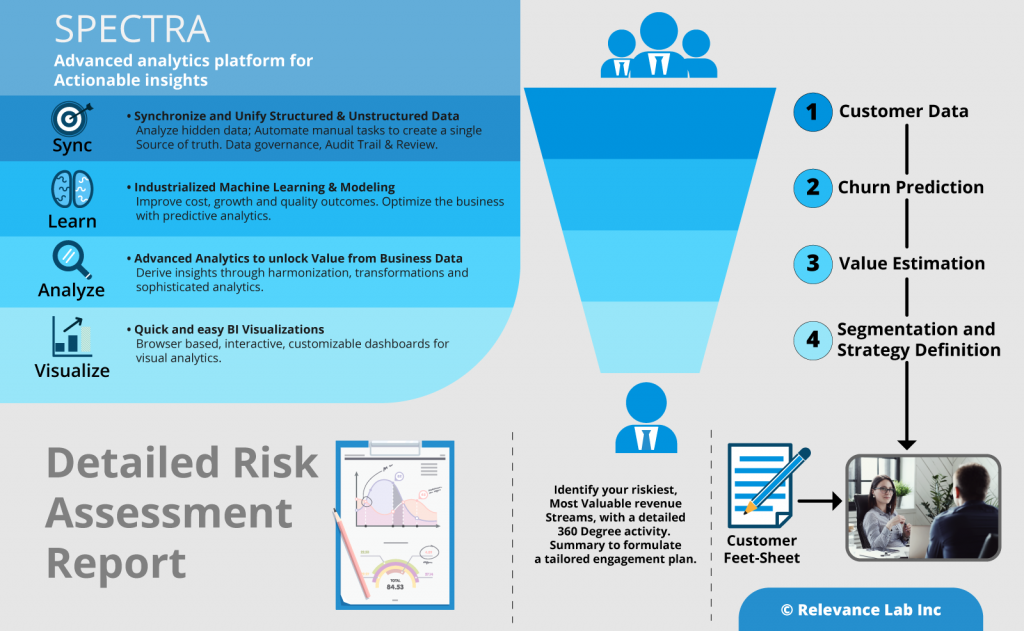
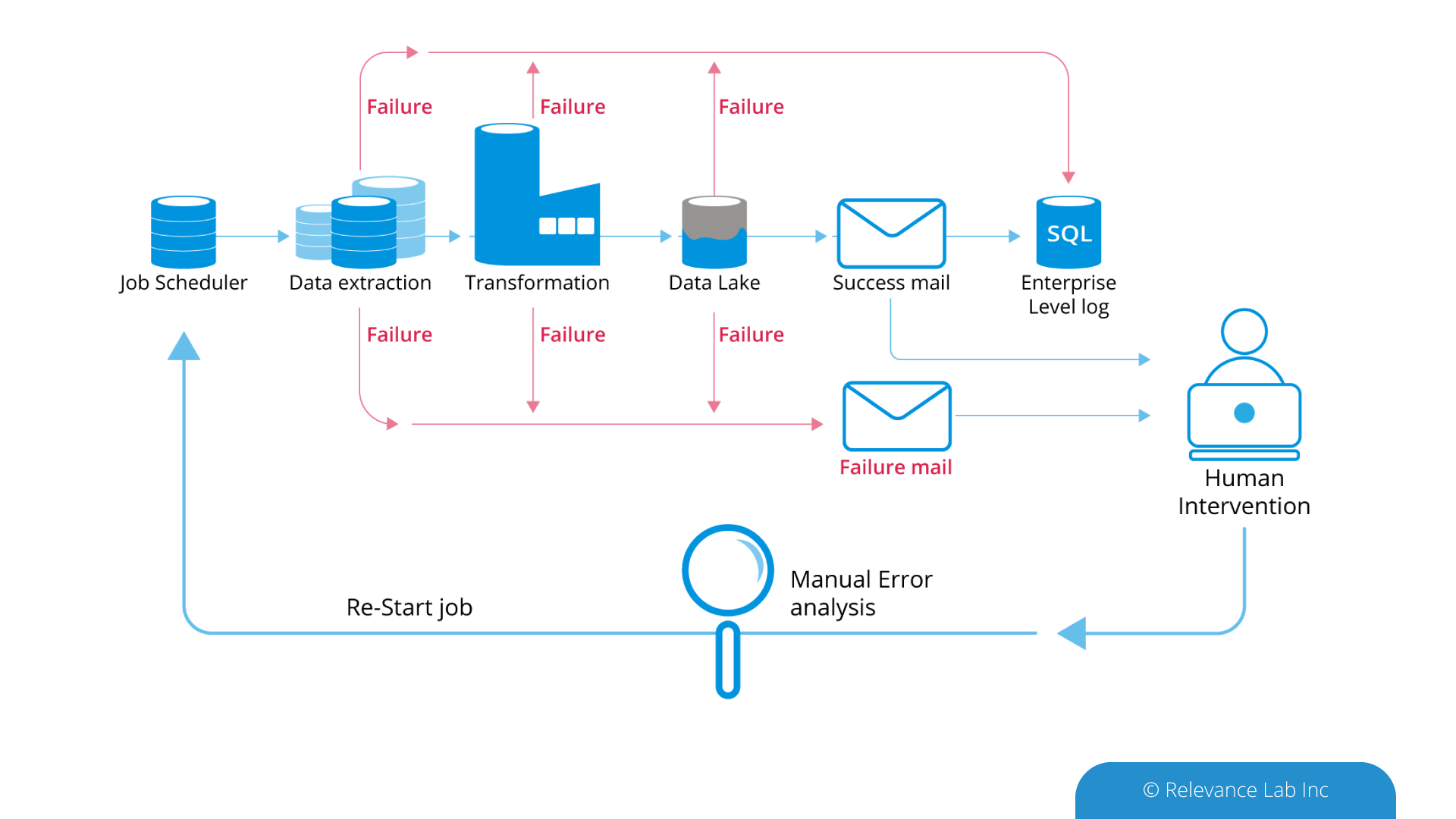
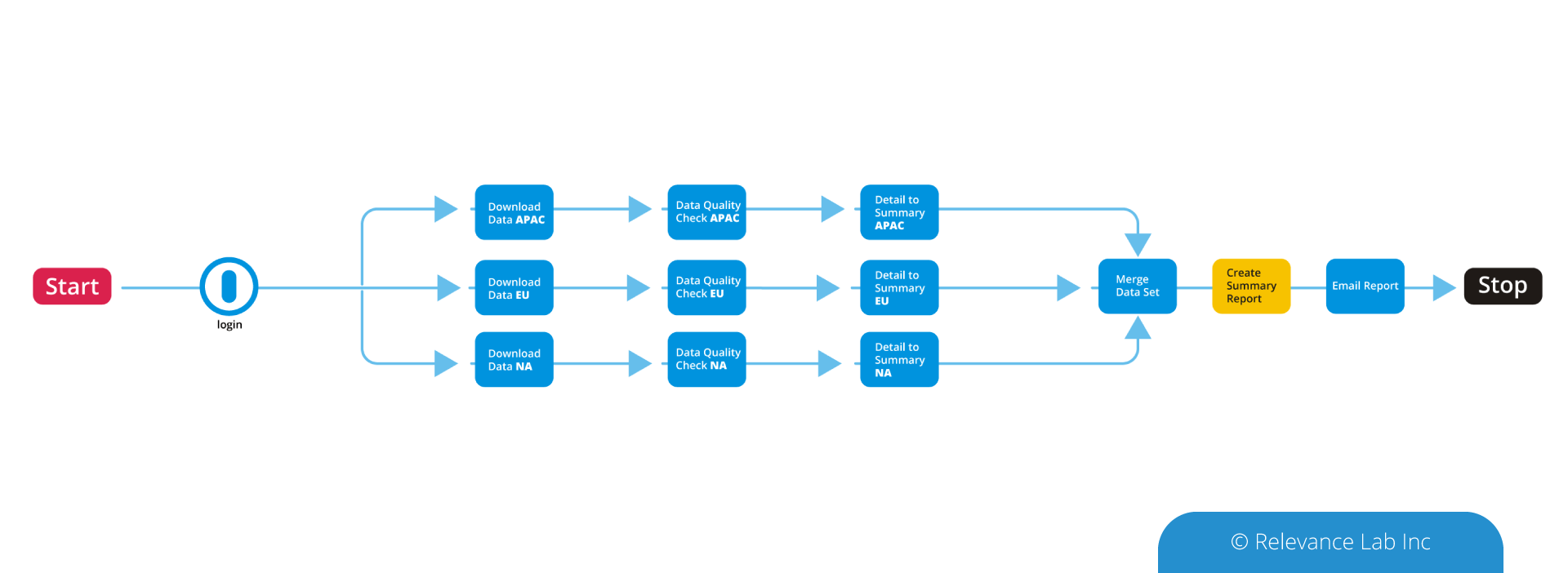
Leveraging data from as many relevant sources (both internal and external) as possible is one of the most important steps in ensuring a responsive global supply chain. The challenge of handling the huge data volume is addressed through the use of big data technologies. The data gathered is then cleansed and harmonized using SPECTRA, Relevancelab big data/analytics platform. SPECTRA can then combine the relevant data from multiple sources, and refresh the results at specified periodic intervals. One point of note here is that Master Data harmonization, that usually consumes months of effort can be significantly accelerated with the SPECTRA’s machine learning and NLP capabilities. - Gain Insights: Know the as-is states from intuitive visualizations
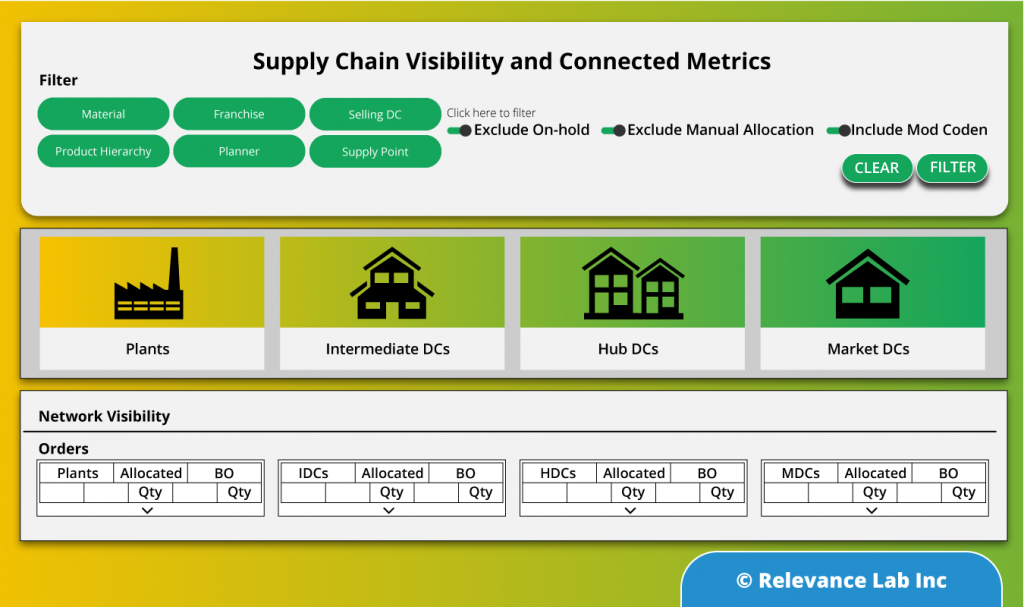
The data pulled in from various sources can be combined to see the snapshot of inventory levels across the supply chain. SPECTRA’s built-in data models and quasi plug and play visualizations ensure that users get a quick and accurate picture of their supply chain. Starting with a bird’s eye view of the current inventory levels across various types of stocking locations and across each inventory type, the visualization capabilities of SPECTRA can be leveraged to have a granular view of the current inventory positions or backlog orders or compare sales with the forecasts. This a critical step in the overall process as this helps organizations to clearly define their problems and identify likely end states. For example, the organization could go for a deeper analysis to identify slow moving and obsolete inventory or fine tune their planning parameters. - Predict: Use big data to predict inventory levels
The data from various systems can be used to predict the likely inventory levels based on service level targets, demand predictions, production and procurement information. Time series analysis is used to predict the lead time for production and procurement. Projected inventory level calculations for future days/weeks, thus calculated, is more likely to reflect the actual inventory levels since the uncertainties, both external and internal, have been well accounted for. - Act: Measurement and Continuous Improvement
Inventory management is a continuous process. The above steps would provide a framework for measuring and tracking the performance of the inventory management solution and make necessary course corrections based on real time feedback.
Conclusion
Successful inventory management is one of the basic requirements for financial success for companies in the Consumer Packaged Goods Sector. There is no perfect solution to achieve this as the customer needs and environment are dynamic and the optimal solution could only be reached iteratively. Relevancelab framework to address inventory management combining deep domain experience with SPECTRA’s capabilities like NLP for faster master data management & harmonization, pre-built data models, quasi plug and play visualizations and custom algorithms offer a faster turn-around and quicker Return-on-Investment. Additionally, the comprehensive process ensures that the data is massaged and prepped for both broader and deeper analysis of the supply chain and risk in the future.
Additional references
https://www.2flow.ie/news-and-blog/solving-the-out-of-stock-problem-infographic
To learn how you can leverage ML and AI within your customer retention strategy, please reach out to marketing@relevancelab.com