Secure Research Environments (SRE) provide researchers with timely and secure access to sensitive research data, computation systems, and common analytics tools for speeding up Scientific Research in the cloud. Researchers are given access to approved data, enabling them to collaborate, analyze data, share results within proper controls and audit trails. Research Gateway provides this secure data platform with the analytical and orchestration tools to support researchers in conducting their work. Their results can then be exported safely, with proper workflows for submission reviews and approvals.
The Secure Research Environments build on the original concept of Trusted Research Environment defined by UK NHS and uses the five safes framework for safe use of secure data. The five elements of the framework are:
Safe people
Safe projects
Safe settings
Safe data
Safe outputs
There are the following key building blocks for the solution:
Data Ingress/Egress
Researcher Workflows & Collaborations with costs controls
On-going Researcher Tools Updates
Software Patching & Security Upgrades
Healthcare (or other sensitive) Data Compliances
Security Monitoring, Audit Trail, Budget Controls, User Access & Management
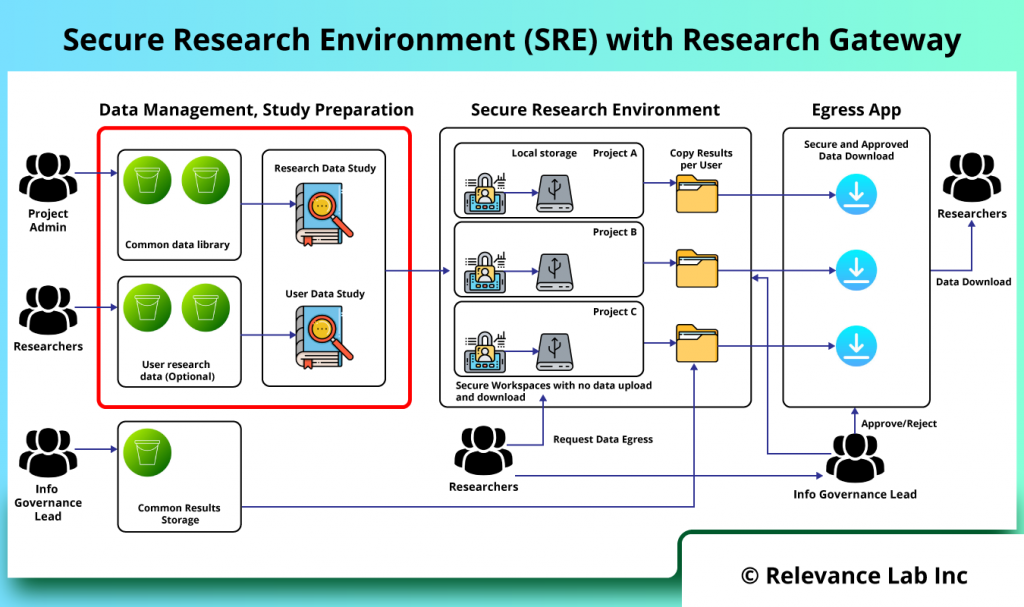
The figure below shows implementation of SRE solution with Research Gateway.
The basic concept is to design a secure data enclave in which there is no ability to transfer data into or out of without going through pre-defined workflows. Within the enclave itself any amount or type of storage/compute/tools can be provisioned to fit the researcher’s needs. There is capability to use common research data and also bring in specific data by researchers.
The core functionality for SRE deals with solutions for the following:
Data Management and Preparation
This deals with “data ingress management” from both public and private sources for research. There are functionalities dealing with data ingestion, extraction, processing, cleansing, and data catalogs.
Study Preparation
Depending on the type of study and participants from different institutions, secure data enclave allows for study specific data preparation, allocation, access management and assignment to specific projects.
Secure Research Environment
A controlled cloud environment is provided for researchers to access the study data in a secure manner with no direct ingress-egress capability and conduct research using common tools like JupyterLab, RStudio, VSCode etc. for both interactive and batch processing. The shared study data is pre-mounted on research workspaces making it easy for researchers to focus on analysis without getting into complexity of infrastructure, tools and costs.
Secure Egress Approvals for Results Sharing
Post research if researchers want to extract results from the secure research environment, a specialized workflow is provided for request, review, approvals, and download of data with compliance and audit trails.
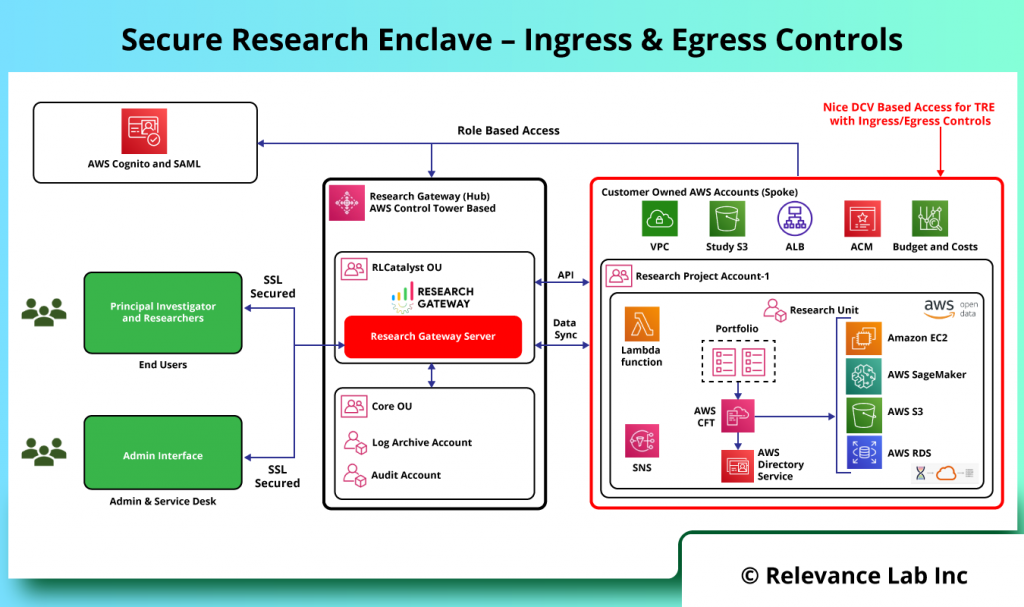
The SRE Architecture provides for Secure Ingress and Egress controls as explained in the figure below.
Building Block
Detailed Steps
Data Management
Project Administrator creates the Data Library and research projects.
Project Administrator selects the Data Library project.
Sets up Study Bucket.
Creates the sub-folders to hold data.
Sets up an Ingress bucket for each researcher to bring in his own data.
Shares this with the researcher.
Project Administrator selects the Study screen.
Creates an internal study for each dataset and assign to the corresponding Secure Research project.
Creates internal study for each ingress bucket.
Project Administrator assigns the researchers to the corresponding secure projects.
Secure Research Environments
Researcher logs in.
Research uploads own data to ingress bucket.
Researcher creates a workspace (secure research desktop).
Researcher connects to workspace.
Researcher runs code and generates output.
Researcher copies output to egress store.
Researcher submits and egress request from the portal.
Egress Application
Information Governance lead logs in to Egress portal.
IG Lead approves request.
Project administrator logs in to portal.
Project administrator approves the request.
IG Lead logs in and downloads the file.
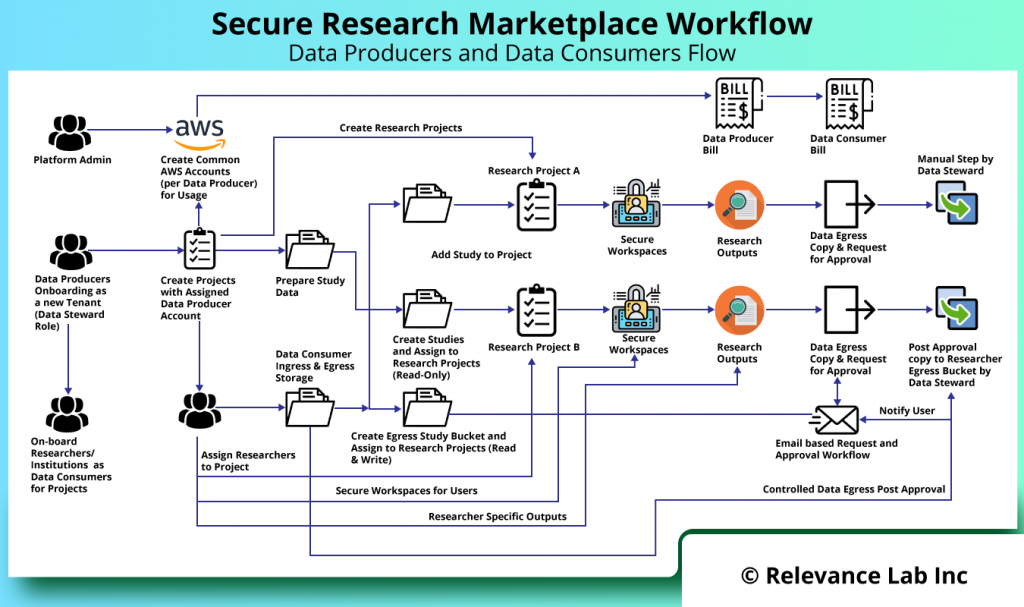
The need for Secure Research Enclave is a growing one across different countries. There is an emerging need for a consortium model, where multiple Data Producers and Consumers need to interact in a Secure Research Marketplace Model. The marketplace model is implemented on AWS Cloud and provides for tracking of costs and billing for all participants. The solution can be hosted by a third-party and provide Software as a Service (SaaS) model driving the key workflows for Data Producers and Data Consumers as explained in figure below.
Summary
Secure Research Environments are key features for enabling large institutions and governmental agencies to speed up research across different stakeholders leveraging the cloud. Relevance Lab provides a pre-built solution that can speed up the implementation of this large scale and complex deployment in a fast, secure, and cost-effective manner.
Major advances are happening with the leverage of Cloud Technologies and large Open Data sets in the areas of Healthcare informatics that include sub-disciplines like Bioinformatics and Clinical Informatics. This is being rapidly adopted by Life Sciences and Healthcare institutions in commercial and public sector space. This domain has deep investments in scientific research and data analytics focussing on information, computation needs, and data acquisition techniques to optimize the acquisition, storage, retrieval, obfuscation, and secure use of information in health and biomedicine for evidence-based medicine and disease management.
In recent years, genomics and genetic data have emerged as an innovative areas of research that could potentially transform healthcare. The emerging trends are for personalized medicine, or precision medicine leveraging genomics. Early diagnosis of a disease can significantly increase the chances of successful treatment, and genomics can detect a disease long before symptoms present themselves. Many diseases, including cancers, are caused by alterations in our genes. Genomics can identify these alterations and search for them using an ever-growing number of genetic tests.
With AWS, genomics customers can dedicate more time and resources to science, speeding time to insights, achieving breakthrough research faster, and bringing life-saving products to market. AWS enables customers to innovate by making genomics data more accessible and useful. AWS delivers the breadth and depth of services to reduce the time between sequencing and interpretation, with secure and frictionless collaboration capabilities across multi-modal datasets. Also, you can choose the right tool for the job to get the best cost and performance at a global scale— accelerating the modern study of genomics.
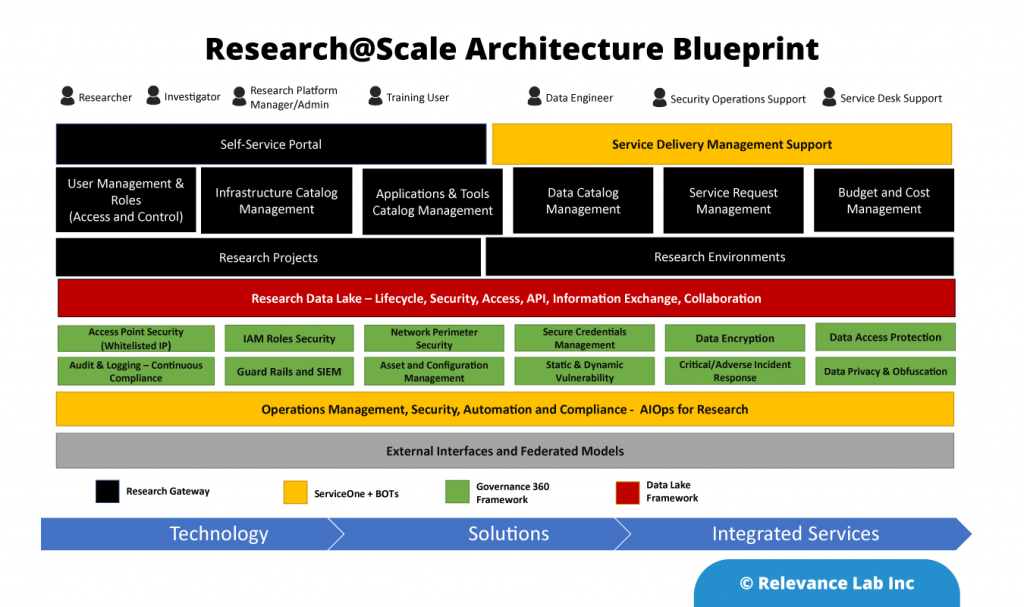
Relevance Lab Research@Scale Architecture Blueprint
Working closely with AWS Healthcare and Clinical Informatics teams, Relevance Lab is bringing a scalable, secure, and compliant solution for enterprises to pursue Research@Scale on Cloud for intramural and extramural needs. The diagram below shows the architecture blueprint for Research@Scale. The solution offered on the AWS platform covers technology, solutions, and integrated services to help large enterprises manage research across global locations.
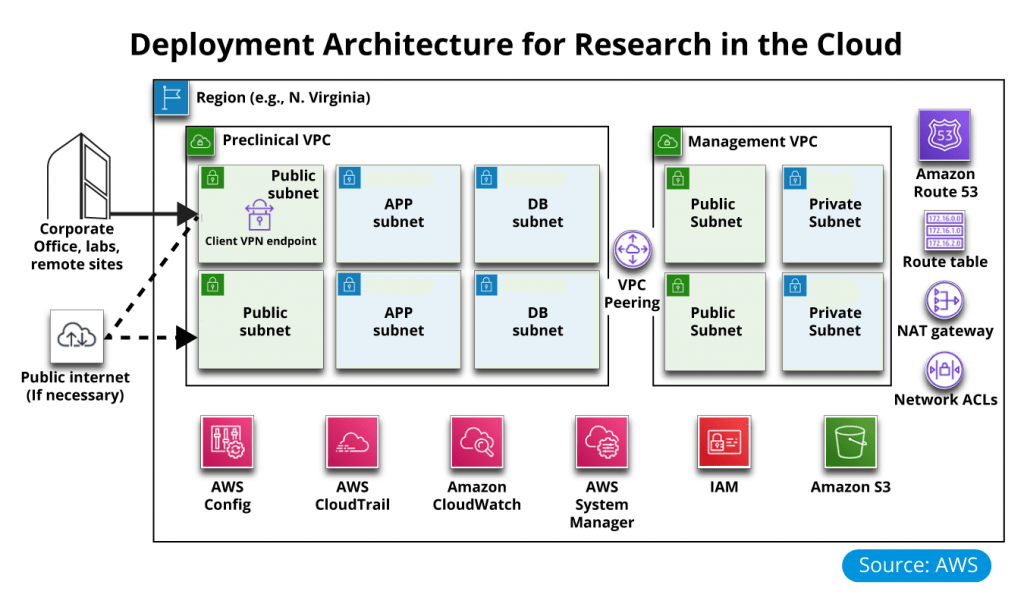
Leveraging AWS Biotech Blueprint with our Research Gateway
Use case with AWS Biotech Blueprint that provides a Core template for deploying a preclinical, cloud-based research infrastructure and optional informatics software on AWS.
This Quick Start sets up the following:
A highly available architecture that spans two availability zones
A preclinical virtual private cloud (VPC) configured with public and private subnets according to AWS best practices to provide you with your own virtual network on AWS. This is where informatics and research applications will run
A management VPC configured with public and private subnets to support the future addition of IT-centric workloads such as active directory, security appliances, and virtual desktop interfaces
Redundant, managed NAT gateways to allow outbound internet access for resources in the private subnets
Certificate-based virtual private network (VPN) services through the use of AWS Client VPN endpoints
Private, split-horizon Domain Name System (DNS) with Amazon Route 53
Best-practice AWS Identity and Access Management (IAM) groups and policies based on the separation of duties, designed to follow the U.S. National Institute of Standards and Technology (NIST) guidelines
A set of automated checks and alerts to notify you when AWS Config detects insecure configurations
Account-level logging, audit, and storage mechanisms are designed to follow NIST guidelines
A secure way to remotely join the preclinical VPC network is by using the AWS Client VPN endpoint
A prepopulated set of AWS Systems Manager Parameter Store key/value pairs for common resource IDs
(Optional) An AWS Service Catalog portfolio of common informatics software that can be easily deployed into your preclinical VPC
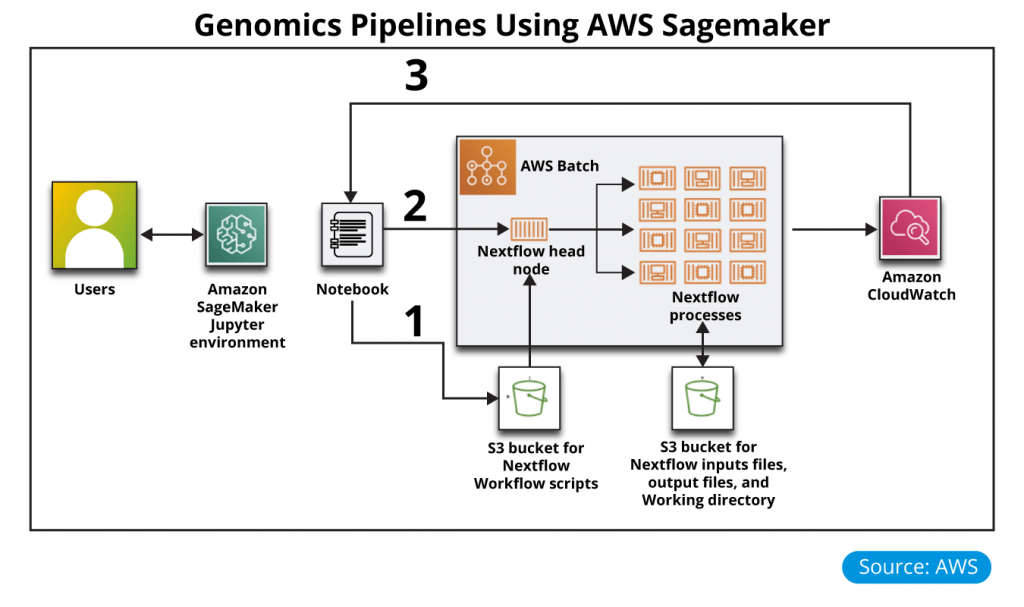
Using the Quickstart templates, the products were added to AWS Service Catalog and imported into RLCatalyst Research Gateway.
Using the standard products, the Nextflow Workflow Orchestration engine was launched for Genomics pipeline analysis. Nextflow helps to create and orchestrate analysis workflows and AWS Batch to run the workflow processes.
Nextflow is an open-source workflow framework and domain-specific language (DSL) for Linux, developed by the Comparative Bioinformatics group at the Barcelona Centre for Genomic Regulation (CRG). The tool enables you to create complex, data-intensive workflow pipeline scripts, and simplifies the implementation and deployment of genomics analysis workflows in the cloud.
This Quick Start sets up the following environment in a preclinical VPC:
In the public subnet, an optional Jupyter notebook in Amazon SageMaker is integrated with an AWS Batch environment.
In the private application subnets, an AWS Batch compute environment for managing Nextflow job definitions and queues and for running Nextflow jobs. AWS Batch containers have Nextflow installed and configured in an Auto Scaling group.
Because there are no databases required for Nextflow, this Quick Start does not deploy anything into the private database (DB) subnets created by the Biotech Blueprint core Quick Start.
An Amazon Simple Storage Service (Amazon S3) bucket to store your Nextflow workflow scripts, input and output files, and working directory.
RStudio for Scientific Research
RStudio is a popular IDE, licensed either commercially or under AGPLv3, for working with R. RStudio is available in a desktop version or a server version that allows you to access R via a web browser.
After you’ve analyzed the results, you may want to visualize them. Shiny is a great R package, licensed either commercially or under AGPLv3, that you can use to create interactive dashboards. Shiny provides a web application framework for R. It turns your analyses into interactive web applications; no HTML, CSS, or JavaScript knowledge is required. Shiny Server can deliver your R visualization to your customers via a web browser and execute R functions, including database queries, in the background.
RStudio is provided as a standard catalog item in Research Gateway for 1-Click deployment and use. AWS provides a number of tools like AWS Athena, AWG Glue, and others to connect to datasets for research analysis.
The volume of genomics data poses challenges for transferring it from sequencers in a quick and controlled fashion, then finding storage resources that can accommodate the scale and performance at a price that is not cost-prohibitive. AWS enables researchers to manage large-scale data that has outpaced the capacity of on-premises infrastructure. By transferring data to the AWS Cloud, organizations can take advantage of high-throughput data ingestion, cost-effective storage options, secure access, and efficient searching to propel genomics research forward.
Workflow automation for secondary analysis
Genomics organizations can struggle with tracking the origins of data when performing secondary analyses and running reproducible and scalable workflows while minimizing IT overhead. AWS offers services for scalable, cost-effective data analysis and simplified orchestration for running and automating parallelizable workflows. Options for automating workflows enable reproducible research or clinical applications, while AWS native, partner (NVIDIA and DRAGEN), and open source solutions (Cromwell and Nextflow) provide flexible options for workflow orchestrators to help scale data analysis.
Data aggregation and governance
Successful genomics research and interpretation often depend on multiple, diverse, multi-modal datasets from large populations. AWS enables organizations to harmonize multi-omic datasets and govern robust data access controls and permissions across a global infrastructure to maintain data integrity as research involves more collaborators and stakeholders. AWS simplifies the ability to store, query, and analyze genomics data, and link with clinical information.
Interpretation and deep learning for tertiary analysis
Analysis requires integrated multi-modal datasets and knowledge bases, intensive computational power, big data analytics, and machine learning at scale, which, historically can take weeks or months, delaying time to insights. AWS accelerates the analysis of big genomics data by leveraging machine learning and high-performance computing. With AWS, researchers have access to greater computing efficiencies at scale, reproducible data processing, data integration capabilities to pull in multi-modal datasets, and public data for clinical annotation—all within a compliance-ready environment.
Clinical applications
There are several hindrances that impede the scale and adoption of genomics for clinical applications including speed of analysis, managing protected health information (PHI), and providing reproducible and interpretable results. By leveraging the capabilities of the AWS Cloud, organizations can establish a differentiated capability in genomics to advance their applications in precision medicine and patient practice. AWS services enable the use of genomics in the clinic by providing the data capture, compute, and storage capabilities needed to empower the modernized clinical lab to decrease the time to results, all while adhering to the most stringent patient privacy regulations.
Open datasets
As more life science researchers move to the cloud and develop cloud-native workflows, they bring reference datasets with them, often in their own personal buckets, leading to duplication, silos, and poor version documentation of commonly used datasets. The AWS Open Data Program (ODP) helps democratize data access by making it readily available in Amazon S3, providing the research community with a single documented source of truth. This increases study reproducibility, stimulates community collaboration, and reduces data duplication. The ODP also covers the cost of Amazon S3 storage, egress, and cross-region transfer for accepted datasets.
Cost optimization
Researchers utilize massive genomics datasets, which require large-scale storage options and powerful computational processing and can be cost-prohibitive. AWS presents cost-saving opportunities for genomics researchers across the data lifecycle—from storage to interpretation. AWS infrastructure and data services enable organizations to save time, money, and devote more resources to science.
Summary
Relevance Lab is a specialist AWS partner working closely in Health Informatics and Genomics solutions leveraging AWS existing solutions and complementing them with its Self-Service Cloud Portal solutions, automation, and governance best practices.
To know more about how we can help standardize, scale, and speed up Scientific Research in Cloud, feel free to contact us at marketing@relevancelab.com.
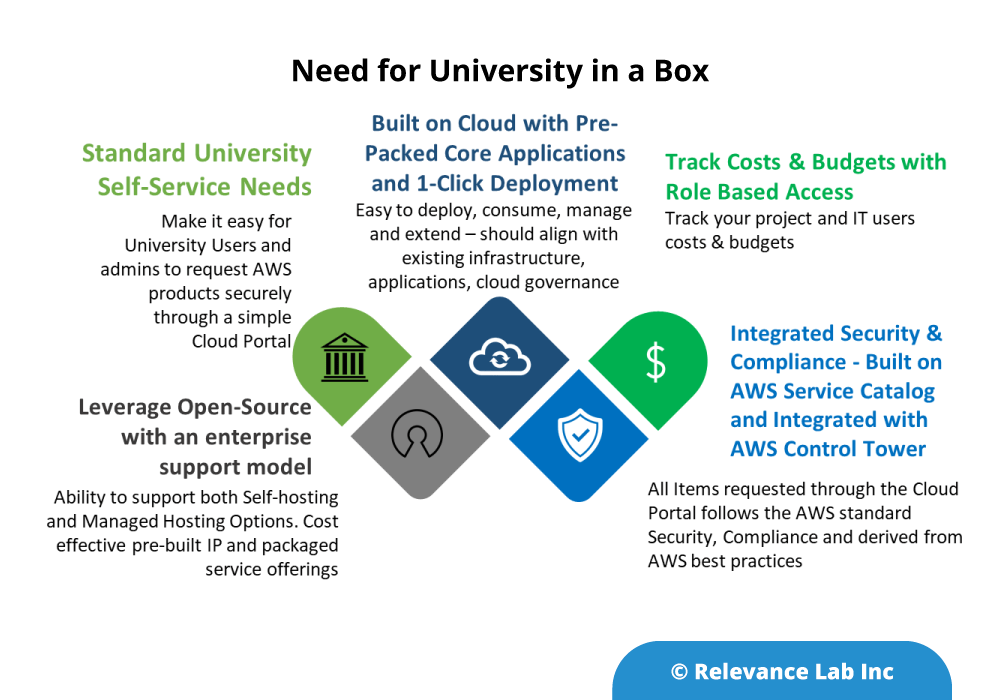
As universities deal with the challenging situation of growing in Post-COVID era there is need for leveraging digital transformation for their computing assets, distributed workforce across multiple campuses, global students and innovative learning & research programs. This requires a technology led program to make education frictionless by leveraging cloud based solutions in a pre-packaged model covering University IT, Learning Needs and Research Computing. Working closely with the AWS partnership in trying to make Digital Learning frictionless, Relevance Lab is bringing a unique new concept to the market of University in a Box, that extends a self-contained Cloud Portal with basic applications to power the needs of a university. This new, radical and innovative concept is based on the idea of a school, college and university going from zero (no AWS account) to cloud native in hours. This enables the Cloud “Mission with Speed” for a mature, secure and comprehensive adoption very fast.
A typical university starting on their cloud journey needs a self-service interactive interface with user logins, tracking and offering the deployed products, provide actions for connectivity after assets are deployed, ability to have lifecycle interactions in UI of Cloud Portal with no need to go to the AWS Console and with a comprehensive view of cost and budgets tracking.
The key building blocks for University In A Box comprise the following:
University Catalog – Cloud Formation Templates useful to Higher Education packaged as Service Catalog Products
Self-Service Cloud Portal for University IT users to order items with security, governance and budget tracking
Easy onboarding model to get started with a hosted option or self-managed instances of Cloud Portal
Leverage existing investments in AWS and standard products the foundational pieces includes a Portfolio of useful software and architectures often used by universities.
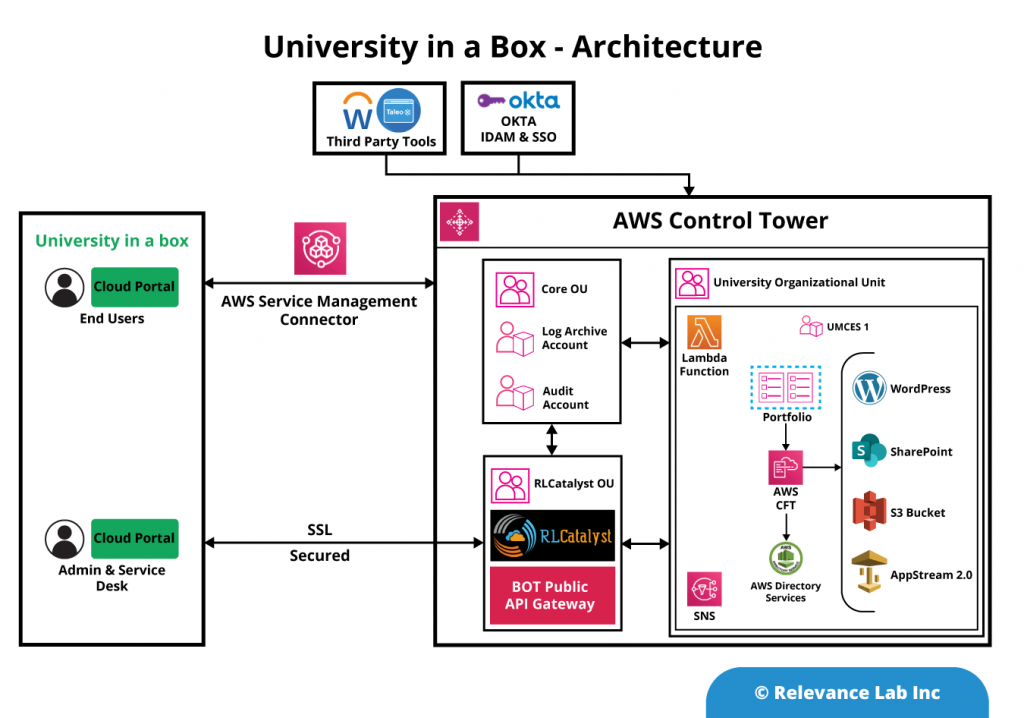
Deploy Control Tower
Deploy GuardDuty
Deploy Security Hub
Deploy VPC + VPN
Deploy AD Extension
Deploy Web Applications SSO, Shibboleth, Drupal
Deploy FSx File Server
Deploy S3 Buckets for Backup Software
Deploy HIPAA workload
Deploy Other solutions as needed, Workspaces, Duo, Appstream, etc
WordPress Reference Architecture
Drupal Reference Architecture
Moodle Reference Architecture
Shibboleth Reference Architecture
How to Setup and Use University in a Box?
The RLCatalyst Cloud Portal solution enables a University with no existing Cloud to deploy a self-service model for internal IT and consume standard applications seamlessly.
Steps for University Specific Setup
Time Taken (Approx)
A new University wants to enable core systems on AWS Cloud and the Root account is created
0.5 Hours
Launch Control Tower and Create Core OU & University OU
1.5 Hours
User and Access Management, Account Creation, Budget Enablement
1 Hour
Network Design of the University Landing Zone (Creation + Configuration)
1.5 Hours
Provision of basic assets (Infra & Applications ) from the standard catalog
1 Hour
Enable Security and Governance (Includes VA, PM, Security Hub)
1.5 Hours
User Training and Handover
1 Hours
The following diagram explains the deployment architecture of the solution.
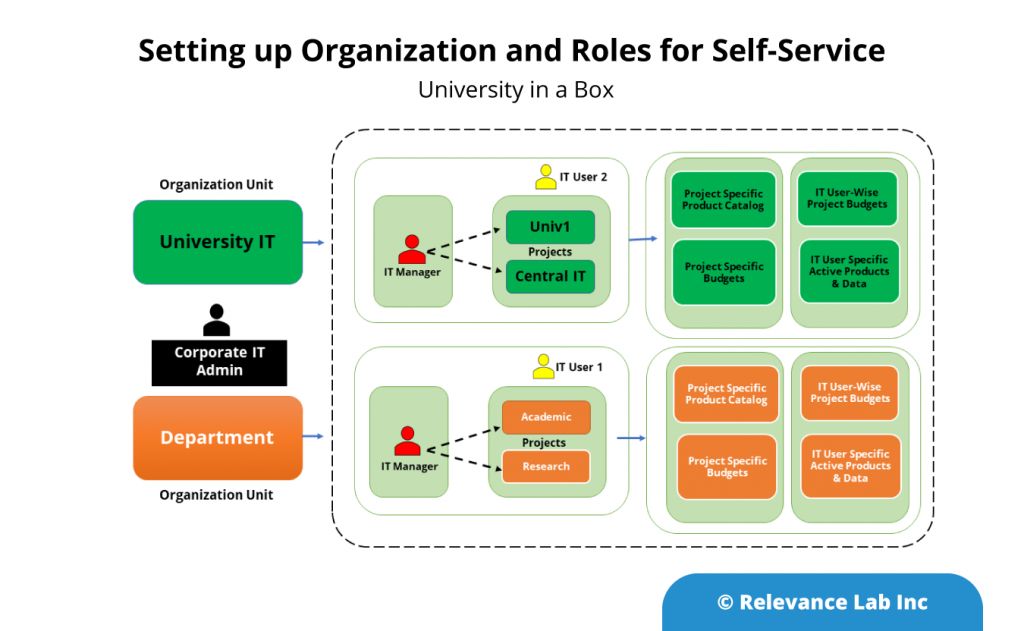
University Users, Roles and Organization Planning
Planning for university users, roles and organizations requires mapping to existing departments, IT and non-IT roles and empowering users for self-service without compromising on security or governance. This can vary between organizations but common patterns are encountered as explained below.
Common Delegation use cases for University IT:
Delegate a product from a Lead Architect to Helpdesk, or a less skilled co-worker
Delegate a product from Lead Architect or Central IT, to another IT group, DBA team, Networking Team, Analytics Team
Delegate a product to another University Department – Academic, Video, etc
Delegate a product to a researcher or faculty member
Setup Planning Considerations on Deployment and Onboarding
Hosting Options
Option:1 – Dedicated Instance per Customer
Option:2 – Hosted Model, Customer brings their AWS account
Option:3 – Hosted Model, RL (Relevance Lab) provides a new AWS account
Initial Catalog Setup
Option:1 – Customer has existing Service Catalog
Option:2 – A default Service Catalog items are loaded from a standard library
Option:3 – Combination of above
Optimizing Setup parameters and Catalog binding for ease of use
Option:1 – Customer fills up details based on best practices and templates provided
Option:2 – RL sets up the initial configuration based on existing parameters
Option:3 – RL as part of new setup, creates an OU, new account and associated parameters
Additional Setup considerations
DNS mapping for Cloud Portal
Authentication – Default Cognito with SAML integration available
Mapping users to roles, organizations/projects/budgets
Standard Catalog for University in a Box Leverages AWS Provided Standard Architecture Best Practices
The basic setup leverages AWS Well Architected framework extensively and builds on AWS Reference Architecture as detailed below.
Sharing a sample Products Preview List based on AWS Provided University Catalog under Open Source Program.
University Catalog Portfolio
Portfolio of useful software and architectures often used by colleges and universities.
WordPress Product with Reference Architecture
This Quick Start deploys WordPress. WordPress is a web publishing platform for building blogs and websites. It can be customized via a wide selection of themes, extensions, and plugins. The Quick Start includes AWS Cloud Formation templates and a guide that provides step-by-step instructions to help you get the most out of your deployment. This reference architecture provides a set of YAML templates for deploying WordPress on AWS using Amazon Virtual Private Cloud (Amazon VPC), Amazon Elastic Compute Cloud (Amazon EC2), Auto Scaling, Elastic Load Balancing (Application Load Balancer), Amazon Relational Database Service (Amazon RDS), Amazon ElastiCache, Amazon Elastic File System (Amazon EFS), Amazon CloudFront, Amazon Route 53, Amazon Certificate Manager (Amazon ACM) with AWS Cloud Formation.
Scale Out Computing Product
Amazon Web Services (AWS) enables data scientists and engineers to manage their scale-out workloads such as high-performance computing (HPC) and deep learning training, without having extensive cloud experience. The Scale-Out Computing on AWS solution helps customers more easily deploy and operate a multiuser environment for computationally intensive workflows such as Computer-Aided Engineering (CAE). The solution features a large selection of compute resources, a fast network backbone, unlimited storage, and budget and cost management directly integrated within AWS. This solution also deploys a user interface (UI) with cloud workstations, file management, and automation tools that enable you to create your own queues, scheduler resources, Amazon Machine Images (AMIs), and management functions for user and group permissions. This solution is designed to be a production ready reference implementation you can use as a starting point for deploying an AWS environment to run scale-out workloads, enabling users to focus on running simulations designed to solve complex computational problems. For example, with the unlimited storage capacity provided by Amazon Elastic File System (Amazon EFS), users won’t run out of space for project input and output files. Additionally, you can integrate your existing LDAP directory with Amazon Cognito to enable users to seamlessly authenticate and run jobs on AWS.
Drupal Reference Architecture
Drupal is an open-source, content management platform written in the PHP server-side scripting language. Drupal provides a backend framework for many enterprise websites. Deploying Drupal on AWS makes it easy to use AWS services to further enhance the performance and extend functionality of your content management framework. This reference architecture provides a set of YAML templates for deploying Drupal on AWS using Amazon Virtual Private Cloud (Amazon VPC), Amazon Elastic Compute Cloud (Amazon EC2), Auto Scaling, Elastic Load Balancing (Application Load Balancer), Amazon Relational Database Service (Amazon RDS), Amazon ElastiCache, Amazon Elastic File System (Amazon EFS), Amazon CloudFront, Amazon Route 53, Amazon Certificate Manager (Amazon ACM) with AWS Cloud Formation.
Moodle Reference Architecture
Moodle is a learning platform designed to provide educators, administrators and learners with a single robust, secure and integrated system to create personalised learning environments. This repository consists of a set of nested templates which deploy a highly available, elastic, and scalable Moodle environment on AWS. Moodle is a learning platform designed to provide educators, administrators and learners with a single robust, secure and integrated system to create personalized learning environments. This reference architecture provides a set of YAML templates for deploying Moodle on AWS using Amazon Virtual Private Cloud (Amazon VPC), Amazon Elastic Compute Cloud (Amazon EC2), Auto Scaling, Elastic Load Balancing (Application Load Balancer), Amazon Relational Database Service (Amazon RDS), Amazon ElastiCache, Amazon Elastic File System (Amazon EFS), Amazon CloudFront, Amazon Route 53, Amazon Certificate Manager (Amazon ACM) with AWS Cloud Formation. This architecture may be overkill for many Moodle deployments, however the templates can be run individually and/or modified to deploy a subset of the architecture that fits your needs.
Shibboleth Reference Architecture with EC2
This Shibboleth IdP reference architecture will deploy a fully functional, scalable, and containerized Shibboleth IdP. This reference architecture includes rotation of IdP sealer keys, utilizing AWS Secrets Manager and AWS Lambda. In addition, the certificates that are part of the IdP as well as some of the LDAP settings (including the username/password) are stored in AWS Secrets Manager. This project is intended to be a starting point for getting the Shibboleth IdP up and running quickly and easily on AWS and provide the foundation to build a production ready deployment around. Be aware that if you do delete the stack, it will delete your CodeCommit repository so your customizations will be lost. Therefore, if you intend to use this for production, it would be a good idea to make a copy of the repo and host it in your own account and take precautions to safeguard your changes.
REDCap on AWS Cloud Formation
This repository contains AWS Cloud Formation templates to automatically deploy a REDCap environment that adheres to AWS architectural best practices. In order to use this automation, you must supply your own copy of the REDCap source files. These are available for qualified entities at projectredcap.org. Once you have downloaded your source files then you can follow the below instructions for deployment. In their own words – REDCap is a secure web application for building and managing online surveys and databases. While REDCap can be used to collect virtually any type of data,including 21 CFR Part 11, FISMA, and HIPAA-compliant environments, it is specifically geared to support online or offline data capture for research studies and operations.
Summary
University in a Box is a powerful example of a specific business problem solved with leverage of Cloud integrated with existing customer specific use cases and easy deployment options to save time, money and achieve quick maturity.
For Universities, colleges and schools trying to use AWS Cloud infrastructure, applications and self-service models the solution can bring significant cost, effort and compliance benefits to help them focus on “Driving Effective Learning” than worrying about enabling cloud infrastructure, basic day to day applications and delegation of tasks to achieve scale. With a combination of pre-built solution and a managed services model to handhold customers with a full lifecycle of development, enhancement and support services, Relevance Lab can be your trusted partner for digital learning enablement.
We use cookies on our website to provide you with a more relevant experience. To learn more about how we use cookies and how you can manage your cookie settings, please refer to our Privacy.
We do not collect and sell your personal information.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You can opt-out of non-necessary cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.