We are delighted to inform that Relevance Lab has partnered with Google Cloud Platform (GCP) as a “Technology Partner” and has been listed in the GCP partner directory. Our product RL Catalyst has also been integrated and certified by GCP.
With GCP increasingly gaining market traction and now being among the top 3 Public Cloud Providers, it is a natural progression of our product strategy to align with GCP. With the integration of RL Catalyst with GCP, we are uniquely positioned to offer our customers an end-to-end integrated DevOps-to-ITOps management story, with ability of Multi & Hybrid Cloud management including our investments around Automation to optimize costs and increase productivity.
With Google’s focus on Data and Business Process solutions and basis their inputs, we also plan to leverage Google Dialog Flow for building enterprise automation solutions around workflows, Chat bots, etc. This is in line with the frictionless business initiatives of most enterprises wherein they want to become more agile by simplifying processes, reduce manual efforts in IT services & costs, optimize IT infrastructure usage & costs, increase business service availability, etc. by leveraging new gen tech like DevOps, Cloud and Automation, while integrating/sun-setting their legacy monolithic apps and IT infrastructure.
Globally, organizations have embraced cloud computing and delivery models for their numerous advantages. Gartner predicts the public cloud market is expected to grow 21.4 percent by the end of 2018, from $153.5 billion in 2017. Cloud computing services provide an opportunity for organizations to consume specific services with delivery models that are most appropriate for them. They help increase the business velocity and reduce the capital expenditure by converting it into operating expenditure.
Capex to Opex Structure
Capital expenditure refers to the money spent in purchasing hardware and in building and managing in-house IT infrastructure. With cloud computing, it is easy to access the entire storage and network infrastructure from a data center without any in-house infrastructure requirements. Cloud service providers also offer the required hardware infrastructure and resource provisioning as per business requirements. Resources can be consumed according to the need of the hour. Cloud computing also offers flexibility and scalability as per business demands.
All these factors help organizations move from a fixed cost structure for capital expenditure to a variable cost structure for the operating expenditure.
Cost of Assets and IT Service Management
After moving to a variable cost structure, organizations must look at the components of its cost structure. They include the cost of assets and the cost of service or cost of IT service management. Cost of assets show a considerable reduction after moving the entire infrastructure or assets to cloud. The cost of service remains vital as it depends on the day-to-day IT operations and represents the day-after-cloud scenario. The leverage of cloud computing can only be realized if the cost of IT service management is brought down.
Growing ITSM or ITOPs Market and High Stakes
While IT service management (ITSM) has taken a new avatar as IT operations management (ITOM), incident management remains the critical IT support process in every organization. The incident response market is expanding rapidly as more enterprises are moving to cloud every year. According to Markets and Markets, the incident response market is expected to grow to $33.76 billion by the year 2023 from $ 13.38 billion in 2018. The key factors that drive the incident response market are heavy financial losses post incident occurrence, rise in security breaches targeting enterprises and compliance requirements such as the EU’s General Data Protection Regulation (GDPR).
Service fallout or service degradation can impact key business operations. A survey conducted by ITIC indicates that 33 percent of enterprises reported that one hour of downtime could cost them $1 million to more than $5 million.
Cost per IT Ticket: The Least Common Denominator of Cost of ITSM
As organizations have high stakes in ensuring that business services run smooth, IT ops teams have additional responsibility in responding to incidents faster without compromising on the quality of service. The two important metrics for any incident management process are 1) cost per IT ticket and 2) mean time to resolution (MTTR). While cost per ticket impacts the overall operating expenditure, MTTR impacts customer satisfaction. The higher the MTTR, the more time it takes to resolve the tickets and, hence, the lower customer satisfaction.
Cost per ticket is the total monthly operating expenditure of the IT ops team (IT service desk) divided by its monthly ticket volume. According to an HDI study, the average cost per service desk ticket in North America is $15.56. Cost per ticket increases as the ticket gets escalated and moves up the life cycle. For an L3 ticket, the average cost per ticket in North America is about $80-$100+.
Severity vs. Volume of IT Tickets
With our experience in managing the cloud IT ops for our clients, we understand that organizations normally look at the volume and severity of IT tickets. They target the High Severity and High Volume quadrants to reduce the cost of the tickets. However, with our experience, we strongly feel that organizations should start their journey with the low hanging fruits such as the Low Severity tickets, which are repeatable in nature and can be automated using bots.
In the next blog, we will elaborate on this approach that can help organizations in measuring and reducing the cost of IT tickets.
About the Author:
Neeraj Deuskar is the Director and Global Head of Marketing for the Relevance Lab (www.relevancelab.com). Relevance Lab is a DevOps and Automation specialist company- making cloud adoption easy for global enterprises. In his current role, Neeraj is formulating and implementing the global marketing strategy with the key responsibilities of making the brand and the pipeline impact. Prior to his current role, Neeraj managed the global marketing teams for various IT product and services organizations and handled various responsibilities including strategy formulation, product and solutions marketing, demand generation, digital marketing, influencers’ marketing, thought leadership and branding. Neeraj is B.E. in Production Engineering and MBA in Marketing, both from the University of Mumbai, India.
I recently attended the LogiPharma 2018 conference in the Penns Landing area of Philadelphia, Pennsylvania. While overlooking the Delaware river, 250+ Pharma Supply Chain Professionals gathered for a productive and interactive, educational show concentrating on various topics related to how positive the impact of the intelligent, digital supply chain is changing the industry, as well as some of the challenges that face organizations as they assess, develop, implement and deploy these technologies.
An overarching theme to several face-to-face meetings we had with supply chain professionals, prospects, partners and new faces, focused directly on the visibility of end-to-end supply chain, analytics, demand planning, inventory management and cold chain management, which especially resonated with the immunotherapy and clinical manufacturers. In the logistics space, IoT is clearly alive and well with intelligent GPS trackers able to read inventory of an entire warehouse, to devices with palette intelligent information, refrigerated scanning and inventory intelligence as well as virtual reality robots delivering packages, which was fun to try out.
The conference kicked off with Brad Pawlowski, Managing Director at Accenture who heads their supply chain practice. His opening remarks focused on the need for an intelligent model in order to successfully connect directly to the customer, creating a network of thousands upon thousands, in order to capture the information of each and every consumer that has a need in the marketplace. In a sea of multiple end-to-end supply chains, he asked the audience, what assets do you want to have? What visibility do you need to have? How do you implement this successfully? He advised that in order to effectively proceed into the future, organizations must become their own control towers, to become “liquid” organizations, in an effort to be as situational, responsive as possible, turning focus to a customer service-oriented model. He ended, by an impactful thought, that data is no longer a noun, it is a verb, and how we use that verb will determine our ability to stay competitive in a field which is changing and expanding rapidly.
The next two days of speakers, round tables, live polling, panels and networking events, dove into the concerns of minimizing risk, maximizing speed and efficiency, training and development of resources, strengthening collaboration, contingency planning, and technology assessment and use cases. Keynote speaker, Chris Mlynek from AbbVie boasted about their ability to get life-saving Parkinson’s and other medications directly to patients in Puerto Rico after Hurricane Maria in 2017. Seeing a video of the patient without his Parkinson’s medication left quite an impactful memory.
After attending LogiPharma 2018, I am more convinced than ever, that a critical success factor for the future of the Pharmaceutical industry lies in the establishment of a digital supply chain. How can we help you with yours?
About the Author:
Amber Stanton is the Senior Director- Business Development at Relevance Lab. She is responsible for the new business growth of the organization in the US region and maintains C-level relationship with key industry executive. Amber has more than 25 years of industry experience in business development, marketing and account management across various industry verticals such as publishing, financial, healthcare, business intelligence and education.
Mckinsey Global Institute Report of 2018 states that Artificial Intelligence (AI) has the potential to create annual value of $3.5 billion -$5.8 billion across different industry sectors. Today, AI in Finance and IT alone accounts for about $100 billion and hence it is becoming quite the game changer in the IT world.
With the onset of cloud adoption, the world of IT DevOps has changed dramatically. The focus of IT Ops is changing to an integrated, service-centric approach that maximizes business services availability. AI can help IT Ops in early detection of outages, potential Root Cause prediction, finding systems and nodes which are susceptible to outages, average resolution time and more. This article highlights a few use cases where AI can be integrated with IT Ops, simplifying day-to-day operations and making remediation more robust.
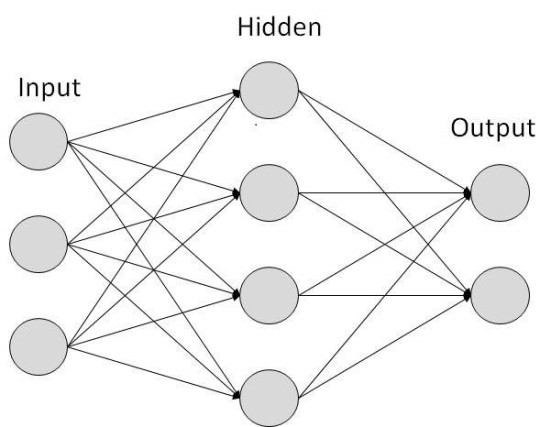
1.) Predictive analytics of outages: False positive causes threat alert fatigue for IT Ops teams. The survey indicates that about 52% of security alerts are generally false positives. This puts a lot of pressure on the teams as they have to review each of these alerts manually. In such a scenario, deep neural networks can predict whether an alert will result into outages.
Alerts Layers Yes/No
Feed Forward back propagation with 2 hidden layers should yield good results in terms of predicting outages as illustrated above. All alert types within a stipulated time can act as inputs and outages would be the output. Historical data should be used to train the model. Every enterprise has its own fault line and weakness, and it is only through historical data that latent features are surfaced, hence every enterprise should build their own customized model as “one size fits all” model has a higher likelihood of not delivering expected outcomes.
The alternate method is a logistic regression where all “alert types” are input variables and “binary outages” would be the output.
Logistic regression measures the relationship between the categorical dependent variables and one or more independent variables by estimating probabilities using a logistic function, which is the cumulative logistic distribution. Thus, it treats the same set of problems as probit regression using similar techniques, with the latter using a cumulative normal distribution curve instead.
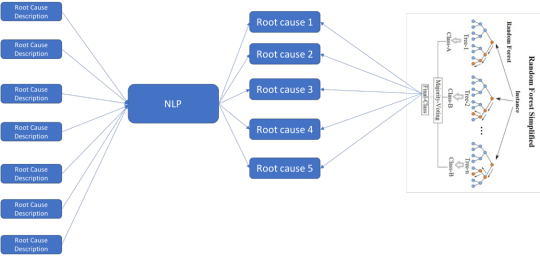
2.) Root Cause classification and prediction: This is a two-step process. In the first step, root cause classification is done based on key word search. From free flow Root Cause Analysis fields, Natural Language Processing (NLP) is used to extract key values and classify into predefined root causes. This can be either supervised or unsupervised.
In the second step, Random Forest for Multi-Class Neural Network can be used to predict root causes while other attributes act as input. Based on the data volume and the datatype, one can choose the right classification model. In general, Random Forest has better accuracy, but it needs structured data and right labeling and it is less fault tolerant to data quality. While Multi-Class Neural Network will need a large volume of data to train, it is more fault tolerant but slightly less accurate.
3.) Prediction of average time to close a ticket: A simple weighted average formula can be used to predict time taken for ticket resolution.
Avg time (t) = (a1.T1 + a2.T2+ a3.T3 )/(count of T1+T2+T3)
Where T1 are ticket types.
Other attributes can be used to segment the ticket into right cohorts to make it more predictable. This helps in better resource planning and utilization. Weightage of features can be done heuristically or empirically.
4.) Unusual Load on System: Simple anomaly detection algorithms can inform whether the system is going through a normal load or it has high variance. A high variance / deviation from average on time series can inform the unusual activities or resources that are not freeing up. However, the algorithm should take care of seasonality as a system load is a function of time and season.
Given the above scenarios it is obvious that AI has a tremendous opportunity to serve IT operations. It can be used for several IT Ops including prediction, event correlation, detection of unusual loads on system (e.g. cyber-attack) and remediation based on root cause analysis.
About the Author:
Vivek Singh is the Senior Director at Relevance Lab and has around 22 years of IT experience in several large enterprises and startups. He is a data architect, an open source evangelist and a chief contributor of Open Source Data Quality project. He is the author of a novel “The Reverse Journey”.
A few days ago, I was traveling from Bangalore to Mumbai. It was an overcast and wet morning and in order to avoid any road traffic delays, I started early so I didn’t have to battle traffic and worry about the prospect of being delayed. At the airport, I checked-in, went through the usual formalities and boarded the flight. I was anticipating a delay, but to my surprise the flight was on time.
While we were approaching the main runway, I could see many flights ahead of us in a queue, waiting for their turn to take-off. At the same time, there were two flights which landed within a couple of minutes of each other. The entire environment of the runway and the surroundings looked terribly busy. While our flight was preparing to take off, the Air Traffic Controller (ATC) tower grabbed my attention. That tall structure, looked very calm in the midst of what seemed chaos, orchestrating every move of all the aircrafts, making sure that the ground operations were smooth, error free and efficient in difficult weather conditions.
I started comparing the runway and airport ground operations with that of the complex IT environment in enterprises today, and the challenges it poses to the IT operations teams. Today, critical business services reside on complex IT infrastructure such as on-premise, cloud and hybrid cloud environments. These require security, scalability and continuous monitoring. But do they have the ATC or the Command Center which can orchestrate, monitor all the IT assets and infrastructure for its smooth functioning? For instance, if the payment service of an e-commerce service provider is down for few minutes, it would have to incur significant losses and impact overall business opportunities creating an adverse impact.
Perhaps, today’s IT operations’ team need one such Command Center, just like an ATC at the airport, so that they can fight down-time, eliminate irrelevant noise in operations and provide critical remediation. This Command Center should have the ability to provide a 360 degree view of the health of the IT infrastructure and availability of business services besides providing the topology view of dependent node structure. This could help in assessing the root cause analysis of a particular IT incident or event occurrence. The Command Center should also provide a complete view of all IT assets, aggregated alerts, outage history and past incident occurrence and related communication enabling the IT team to predict the future occurrence of such events or incidents to prevent the outages of critical business services. In case these outages or incidents did occur, it would be a boon for the IT operations team if a Command Center could provide critical data driven insights and suggest remedial actions which in turn could be provisioned with proactive BOTs.
While I arrived at my destination on time- thanks to the ATC which made it possible, despite the challenging and complex weather conditions. This brings me to a critical question that I need to ask -do you have the required ATC or Command Center for IT Operations which can help you sustain, pre-empt and continue with business operations in a complex IT environment?
About the Author:
Neeraj Deuskar is the Director and Global Head of Marketing for the Relevance Lab. Relevance Lab is a DevOps and Automation specialist company- making cloud adoption easy for global enterprises. In his current role, Neeraj is formulating and implementing the global marketing strategy with the key responsibilities of making the brand and the pipeline impact. Prior to his current role, he has managed the global marketing teams for various IT product and services organizations and handled various responsibilities including strategy formulation, product and solutions marketing, demand generation, digital marketing, influencers’ marketing, thought leadership and branding. Neeraj is B.E. in Production Engineering and MBA in Marketing, both from the University of Mumbai, India.
As per analysts’ forecasts, revenue generated by global B2B players from their online platforms is expected to reach US$6.7 trillion in sales worldwide by 2020. While more & more B2B players are going online, it needs to be noted that B2B models are more complex than B2C models, e.g.:
Higher frequency of transactions per customer & order volumes
Price fluctuations and longer-term contracts & business relationships
Need for multiple user management, levels of approvals/workflows
Specific to the High-Tech distribution industry (comprising of distributors in IT, Telecom, Consumer Electronics, etc.), they are being disrupted with:
Shrinking margins in traditional business models
New entrantscoming with online models
Shift in Enterprise Buying Behaviorfrom “Asset” (Capex) to “On-Demand Use” (Opex)
Push from OEMsto re-model business – from “offline and volume” to “online and value”
These triggers are driving their need for:
Wider set of offerings to cater across larger geographies
Bundled offerings to re-orient from “transaction” to “lifecycle”, with higher margins
Real time visibilitywith Analytics across the Supply Chain for better efficiencies
“Self-Service” Portals for better user experienceand information on-demand
Managing renewalsefficiently and timely
Our “RL Catalyst Cloud Marketplace” solution covers their business processes like:
Partner/Reseller Registration, On-boarding, Credit limit, Order Placement & Billing
The value that our solution drives include Increased Revenues, Reduced Cost of Operations, Increased Efficiencies & Faster Time to Market. It also covers the need for “Day After Cloud” management with “RL Catalyst ArcNet Command Center” for providing integrated Cloud Care services, which makes it a differentiated solution for Distributors, CSPs, MSPs and Hosting Providers.
We further believe the context, applicability and value of this solution is also relevant for B2B Distributors in other industries with a multi-layer distribution model like Pharma, FMCG, CPG, Automotive, etc. – where Cloud-driven online business models are driving them towards Digital Transformation.
In today’s world where Cloud has become all-pervasive and must-have, the questions around Cloud are moving away from “Why Cloud”, “What are the benefits”, types to “How to move to Cloud”, “How to optimally use Cloud”, etc. In this blog, we are going to talk about how RLCatalyst (DevOps and Automation product from Relevance Lab) can be leveraged for efficient and effective Cloud Migration.
While there is no single universally accepted approach for Cloud migration, organisations and service providers often depend on the goals & objectives, existing landscape & architecture, toolsets and guidelines to achieve cloud adoption. Relevance Lab’s Cloud migration approach advocates a 4-stage structured methodology of DISCOVER →ASSESS → PLAN → MIGRATE (DAPM), involving consulting services and its RLCatalyst product.
In the Discover stage, we identify and document the entire inventory planned for the migration – applications, infrastructure and dependencies. Studying the characteristics of each of these will help in the next phase – Assessment. Organisations which maintain the inventory may skip this step and do the assessment directly based on the inventory.
The Assess stage is the crucial step that defines whether a migration candidate qualifies for migration. Some of the factors that need to be determined here are Business considerations (like whether the applications have highly sensitive customer data which requires high security, what are the Disaster Recovery requirements of the applications, etc.) and Technical Considerations (like whether the applications are customized and are integrated with lot of components, whether the applications are tightly bound to on-premise applications, etc.).
In the Plan stage, a migration plan is worked out covering the goals/objectives of migration, identified apps with dependency plans (if any), what tools to use to discover/assess/migrate, target architecture, target cloud (decided based on cost, performance, support etc.), migration strategy (Lift and Shift or Virtualisation & Containerisation, etc.), expected business benefits.
While the above 3 stages are mostly consulting oriented, its in the final stage of Migrate that a tool usage kicks in. While a 100% automated migration is not practically possible, RLCatalyst accelerates migration with some of its in-built capabilities around provisioning of target environment, orchestration & post migration monitoring support, as in:
Infrastructure Automation: The first step in executing the migration is to setup the target environment as per the outcome of the assessment phase. With RLCatalyst you can do this in 2 phases
Use the base templates available in the product to setup the base infrastructure
Create templates for specific software stacks and applications which can be run on top on basic infrastructure
Ongoing Workload Migration Automation: For the subsequent workload migration post the initial set, you can reuse the RLCatalyst templates and blueprints
BOTs accelerated Migrations: Use RLCatalyst BOTs to manage applications/services/processes post migration
Once migration/move to Cloud is complete, the next big focus area for enterprises becomes managing the “Day After” (Post-Migrate). Optimally using the Cloud is key to achieve the overall Cloud Migration program objectives. A “global Cloud pioneer-cum-born in the Cloud company” once told us “DevOps is the right way to manage Cloud”. Along with DevOps, Automation concepts can also be leveraged to use Cloud resources effectively by extending the coverage to IT Service Ops.
RLCatalyst helps Enterprises transition to a “Managed Model” of their existing Data Center and Cloud assets and enables Cloud Monitoring and Optimization.
RLCatalyst Command Centre helps in monitoring all your assets (including multi/hybrid Cloud scenarios) and also tracking KPIs like capacity, usage, compliance, costs, etc. more effectively
RLCatalyst “Automation First” BOTS provides a pre-built “Automation Library” of assets (BOTS), with which one can quickly achieve standardization, self-service IT, 1-Click deployment, real-time monitoring, proactive remediation capabilities etc. leading to reduced manual efforts in IT services delivery
RLCatalyst CI/CD Cockpit helps you seamlessly manage multiple projects across environments, thereby helping you achieve faster time-to-market
We use cookies on our website to provide you with a more relevant experience. To learn more about how we use cookies and how you can manage your cookie settings, please refer to our Privacy.
We do not collect and sell your personal information.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You can opt-out of non-necessary cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.